


Ad Hoc Querying on Streaming Big Data
Strategies, Best Practices, and Performance Insights for Real-Time Analytics


Ad Hoc Querying Motivation
Imagine you are monitoring a live data stream from an IoT sensor network or tracking real-time customer interactions on a website. In these scenarios, data flows continuously and provides insights as events occur. Yet there are times when you need to pause and investigate specific issues.
Ad hoc querying of streaming data is a common challenge in data engineering.
Whether you are debugging by checking for duplicate messages or null columns, generating real-time metrics, or powering backend customer-facing applications, the ability to quickly and efficiently interrogate streaming data is a true superpower for data organizations.
In this post we explore why traditional streaming solutions such as Kafka are not built for ad hoc queries, delve into a range of architectural solutions, provide background information for those with basic Kafka knowledge, and discuss performance considerations to help you choose the right strategy for your use case.
Understanding Kafka and Streaming
Apache Kafka is a distributed streaming platform designed for high-throughput and fault-tolerant pub/sub messaging.
Its core strengths include:
• Stream Ingestion: Kafka efficiently ingests small batches of data in near real-time.
• Durability and Scalability: The platform allows data retention over time while ensuring high availability.
• Low-latency Processing: It delivers data to consumers almost immediately.
Kafka’s architecture is optimized for continuous data processing rather than large, ad hoc batch queries. While this design makes Kafka excellent for real-time data pipelines, it poses challenges for ad hoc query scenarios.
Why Streaming Solutions Struggle with Ad Hoc Queries
Ad hoc queries often require reading and processing large amounts of data at once. Streaming solutions such as Kafka are optimized for:
• Small Batch Processing: Handling continuous streams of small data segments.
• Pub/Sub Messaging: Distributing messages quickly to multiple consumers.

When ad hoc queries demand large data scans, this results in high CPU and disk usage as the system attempts to read massive datasets. Query responses may be slow or inconsistent.
For example, Confluent's KSQL is designed to provide a continuous stream of responses for real-time operations rather than the batch responses needed for ad hoc analysis.
Architectural Solutions for Ad Hoc Querying
Given these limitations, several strategies have emerged to enable efficient ad hoc querying on streaming data.
Solution 1: Ingest to Data Lake
The simplest and most cost-effective solution I recommend is to stream ingest the data to a data lake in small batches (between 1-5 minutes) and then use any data lake solution available in your stack to query the data.

Advantages:
Assuming the organization has an existing stream ingestion to data lake tooling - there is no additional tools needed to be added to the stack
You pay only for compute when you use the query the data. This is especially true for serverless solutions such as AWS Athena and Databricks Serverless.
Data lake object storage (such as S3) is much cheeper compared to kafka retention, and retention is not limited such as with Kafka. After implementation can reduce your Kafka retention and use the S3 ingested data instead.
Backfill is much easier and cheeper from S3 than via Kafka. As discussed, Kafka optimized for steaming ingest in small batches and not large batches.
Disadvantages:
Data freshness is around 1-5 minutes
Query latency is dependent on data lake engines performance, which can take seconds to minutes to return a response
Creates a lot of small files. In the case of 1 minute batches that reads from 60 kafka partitions, there will be 60 source kafka partitions * 60 minutes * 24 hours = 86,400 files per day. As a result, for example checking duplicated for the last day could be very slow and inefficient
Solution 2: Ingest to Iceberg Table with Compaction
Utilize table formats like Apache Iceberg or Delta Lake to organize streaming data. Implement periodic compaction (for example, every hour) to merge small files into larger, more query-efficient files.

Advantages
• Compaction reduces the number of files to read, significantly improving query performance (for example, reducing 86,400 files to around 83 files for recent data).
• Managed services (such as AWS S3 Tables) help minimize maintenance overhead.
Disadvantages
• Requires an additional process to manage table maintenance and perform compaction.
• Adds another layer of operational complexity to the data pipeline.
Solution #3 - OLAP engine
Adopt an Online analytical processing (OLAP) engine that reads directly from S3, such as Druid, Kurrent, RisingWave, or ClickHouse (with S3 table support). This approach provides sub-second query performance on fresh data while separating compute from storage.
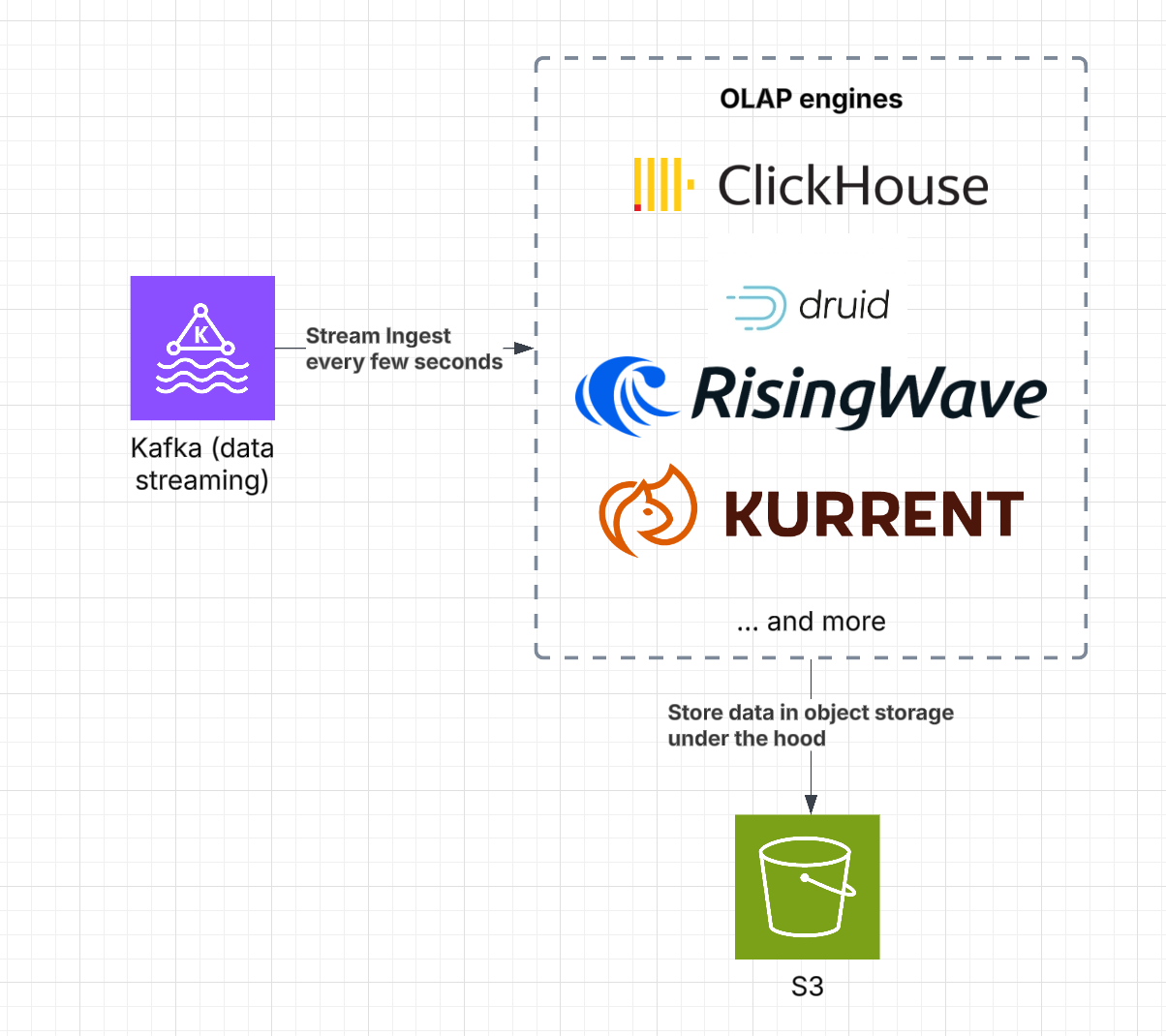
Advantages
• Low latency with sub-second responses for interactive queries.
• Optimized for fast aggregations and complex analytical queries.
Disadvantages
• Requires integration and configuration of an additional system.
• Generally incurs higher compute costs compared to basic data lake query engines.
Solution 4: Direct Read from Kafka (HACK)
Surprisingly, although it’s not optimized there is an official Trino driver to configure a direct read from Kafka!

Here is an example configuration for Apache Trino:

Advantages
• Simplifies the system by eliminating extra components.
Disadvantages
• This approach is not optimized for ad hoc queries, leading to significant performance degradation in both Kafka and Trino.
• The system is likely to face scalability challenges due to CPU and disk I/O bottlenecks.
Solution 5: Dedicated Tooling
Specialized tools for data analytics on streaming data are emerging.

Advantages
• Purpose-built for the challenges of streaming data analytics.
• Reduces the overhead of managing custom ingestion pipelines and multiple components.
Disadvantages
• These tools are relatively new, and organizations must carefully consider build versus buy decisions.
• May involve licensing fees or additional operational expenses.
We predict more tooling like this will appear in the near future, as the overhead of setting up an ad-hoc query solution for each stream in the organization is massive.
Performance Considerations
When tackling ad hoc queries on streaming data, performance is critical. Consider the following aspects:
• Data Freshness and Query Latency
Data lakes offer cost-effective storage and scalability but introduce a slight delay and variable query times.
OLAP engines provide sub-second responses at the expense of increased complexity and higher compute costs.
• File Management
Frequent ingestion can lead to an overwhelming number of small files that degrade query performance.
Implementing compaction strategies using formats like Iceberg or Delta Lake can consolidate files and improve performance.
• Resource Utilization
Direct queries on streaming systems such as Kafka can spike CPU and disk I/O.
Offloading heavy queries to optimized query engines or OLAP systems can better manage resource usage.
• Cost Implications
Storing data in a data lake is often less expensive than maintaining long-term Kafka retention.
However, the cost of compute during query time must be carefully evaluated, especially with managed services that balance operational overhead and performance.
Summary
Being able to do ad-hoc queries is a superpower for data organizations.
While Kafka and similar streaming solutions excel at real-time data ingestion and distribution, they are not designed for ad hoc query use cases.
For debugging and retrospective analyses, consider using a data lake (Solution 1) or an Iceberg table with compaction (Solution 2). For real-time, user-facing queries, an OLAP engine (Solution 3) is preferable. Direct reads from Kafka (Solution 4) or dedicated tooling (Solution 5) may be suitable in scenarios where the query need is less critical or when evaluating build versus buy decisions.
By carefully considering data freshness, query performance, and operational constraints, you can architect a system that unlocks the full potential of ad hoc querying on streaming data.
If you found these insights helpful, subscribe to Big Data Performance Weekly for more expert tips and updates.