
Apache Spark Declarative Pipelines: The Evolution from Imperative to Declarative Data Engineering - Part 1
Everything You Need to Know About Apache Spark 4.1's Game-Changing Declarative Pipeline Feature

Apache Spark 4.1 is set to introduce a game-changing feature: Declarative Pipelines. This major addition, tracked in [SPIP-51727], represents the next evolutionary step in Spark's journey toward making data engineering more accessible and reliable.
Declarative Pipelines address a fundamental challenge in modern data engineering: as data volumes grow and business demands for real-time analytics increase, the traditional imperative approach to building data pipelines is showing its limitations. Instead of writing complex orchestration code to manage job dependencies, handle failures, and coordinate batch and streaming workloads, engineers can now simply declare what they want their data pipeline to produce, and let Spark figure out how to execute it efficiently.
This shift promises to reduce pipeline development time by up to 90% while dramatically improving reliability and maintainability. But to understand why this matters, let's start with a familiar scenario that every data engineer has faced.


From Simple Scripts to Complex Orchestration Nightmares
Let's start with a familiar scenario. You're a data engineer, and the business team asks you to filter sales data based on quantity. Simple enough, you write a straightforward Spark job:
from pyspark.sql import SparkSession import os spark = SparkSession \ .builder \ .appName("Sales Filterer") \ .config("spark.jars.packages", "io.dataflint:spark_2.12:0.4.0") \ .config("spark.plugins", "io.dataflint.spark.SparkDataflintPlugin") \ .config("spark.ui.port", "11000") \ .config("spark.sql.maxMetadataStringLength", "10000") \ .master("local[1]") \ .getOrCreate() df = spark.read.load(os.getenv('SALES_FILES_LOCATION')) df_filtered = df.filter(df.ss_quantity > 1) df_filtered.repartition("ss_quantity").write \ .mode("overwrite") \ .partitionBy("ss_quantity") \ .parquet("/tmp/store_sales") spark.stop()
This works perfectly.
But then the business comes back with more requests: "We also need daily aggregations, rolling 7-day summaries, and real-time updates when new data arrives."
Suddenly, your simple script becomes a complex web of interdependent jobs, each requiring careful orchestration, error handling, and monitoring.
This is where many data engineering teams find themselves trapped—spending more time managing pipeline orchestration than solving actual business problems.
The Declarative Revolution: A Brief History
Apache Spark's journey toward declarative programming has been evolutionary, with each major release addressing specific pain points in data processing, as spark matured it also abstracted away many capabilites in order to improve the dev experiance:
2012: The RDD Era - Pure Imperative Programming
Spark began with Resilient Distributed Datasets (RDDs), a powerful but low-level abstraction. With RDDs, developers had to explicitly orchestrate every transformation:
// The old RDD way - very explicit val rdd = spark.sparkContext.textFile("data.txt") val words = rdd.flatMap(_.split(" ")) val wordCounts = words.map((_, 1)).reduceByKey(_ + _)
While powerful, RDDs required deep Spark knowledge and left optimization entirely to the programmer.
2015: DataFrames and the First Taste of Declarative Programming
Spark 1.3 introduced DataFrames, marking the first major shift toward declarative programming. Instead of telling Spark how to perform operations, developers could express what they wanted:
# Much more declarative df.groupBy("category").agg(sum("sales")).orderBy("category")
The Catalyst optimizer would automatically plan efficient execution, but this still operated at the level of individual queries.
2019-2021: The Lakehouse Foundation
The open-sourcing of Delta Lake in 2019 provided reliable data storage with ACID transactions. Then in 2021, Databricks introduced Delta Live Tables (DLT), the first true declarative ETL framework for Spark. DLT allowed users to declare what tables should exist and how to derive them, with the system handling orchestration automatically.
2025: The Open Source Transformation
In a pivotal move at the 2025 Data+AI Summit, Databricks donated the core declarative pipeline framework to Apache Spark through Spark Improvement Proposal SPIP-51727. This brings declarative pipeline capabilities to the entire Spark ecosystem, not just Databricks users.
Why Declarative Pipelines? The Pain Points They Solve
The motivation for Spark Declarative Pipelines stems from real pain points that data engineering teams face daily:
1. Eliminating Orchestration Toil
In traditional approaches, engineers spend enormous effort writing "glue code" to chain Spark jobs together. Consider managing incremental loads, handling dependencies, and dealing with late-arriving data; these are all "undifferentiated heavy lifting" that distract from business logic.
2. Coping with Schema Evolution
As data sources evolve, imperative pipelines become brittle. A schema change upstream can break downstream jobs unless meticulously handled. Declarative pipelines validate dependencies upfront, catching incompatibilities before execution.
3. Unified Batch and Streaming
Many teams maintain separate codebases for batch ETL and streaming processes, leading to duplicated logic and increased complexity. Declarative pipelines encourage a single pipeline definition that handles both continuous and scheduled updates.
4. Reducing Technical Debt
Over time, imperative pipelines accumulate complex DAGs with ad-hoc fixes. Declarative frameworks enforce standardized patterns and provide built-in capabilities for common requirements, leading to more consistent, maintainable code.

From Imperative Chaos to Declarative Clarity
Let's see how our original sales filtering example transforms using declarative pipelines:
# sales_pipeline.py - open-source Spark 4.1 style from spark.pipelines import table, flow, run import os, pyspark.sql.functions as F from pyspark.sql.window import Window # ⇢ source ─────────────────────────────────────────── @table(name="sales_raw", spark_conf={ "spark.jars.packages": "io.dataflint:spark_2.12:0.4.0", "spark.plugins": "io.dataflint.spark.SparkDataflintPlugin"}) def sales_raw(): return spark.read.load(os.getenv("SALES_FILES_LOCATION")) # ⇢ filter ─────────────────────────────────────────── @table(name="sales_filtered", partition_cols=["ss_quantity"], mode="overwrite") def sales_filtered(): return sales_raw().filter("ss_quantity > 1") # ⇢ aggregate ─────────────────────────────────────── @table(name="daily_sales") def daily_sales(): return (sales_filtered() .groupBy("ss_sold_date_sk") .agg(F.sum("ss_quantity").alias("daily_quantity"))) # ⇢ 7-day roll-up ──────────────────────────────────── @table(name="rolling_7d") def rolling_7d(): w = Window.orderBy("ss_sold_date_sk").rowsBetween(-6, 0) return daily_sales().withColumn( "rolling_7d_quantity", F.sum("daily_quantity").over(w)) # Declare the end-state you care about flow(name="sales_pipeline", targets=["rolling_7d"]) if __name__ == "__main__": run() # Spark infers the DAG and executes it
Notice the transformation:
No explicit orchestration: We declare what each table should be, not how to sequence the operations
Automatic dependency resolution: Spark infers that
rolling_7ddepends ondaily_sales, which depends onsales_filtered, etc.Built-in optimization: The framework handles incremental processing, parallel execution where possible, and automatic retries
Unified API: The same pipeline definition works for both batch and streaming scenarios
Execution Flow
When you run this pipeline, Spark:
Analyzes the dependency graph: Validates that all referenced inputs exist and checks for dependency cycles
Creates an optimized execution plan: Determines the correct order and identifies opportunities for parallelism
Executes with Catalyst optimizations: Each transformation benefits from Spark's query optimizer
Manages state and checkpoints: Handles incremental processing and failure recovery automatically
So how it changes the ecperieince?
Best way to gauge the change is to compare various dev development aspects and comapre them, hope it helps convey the change:
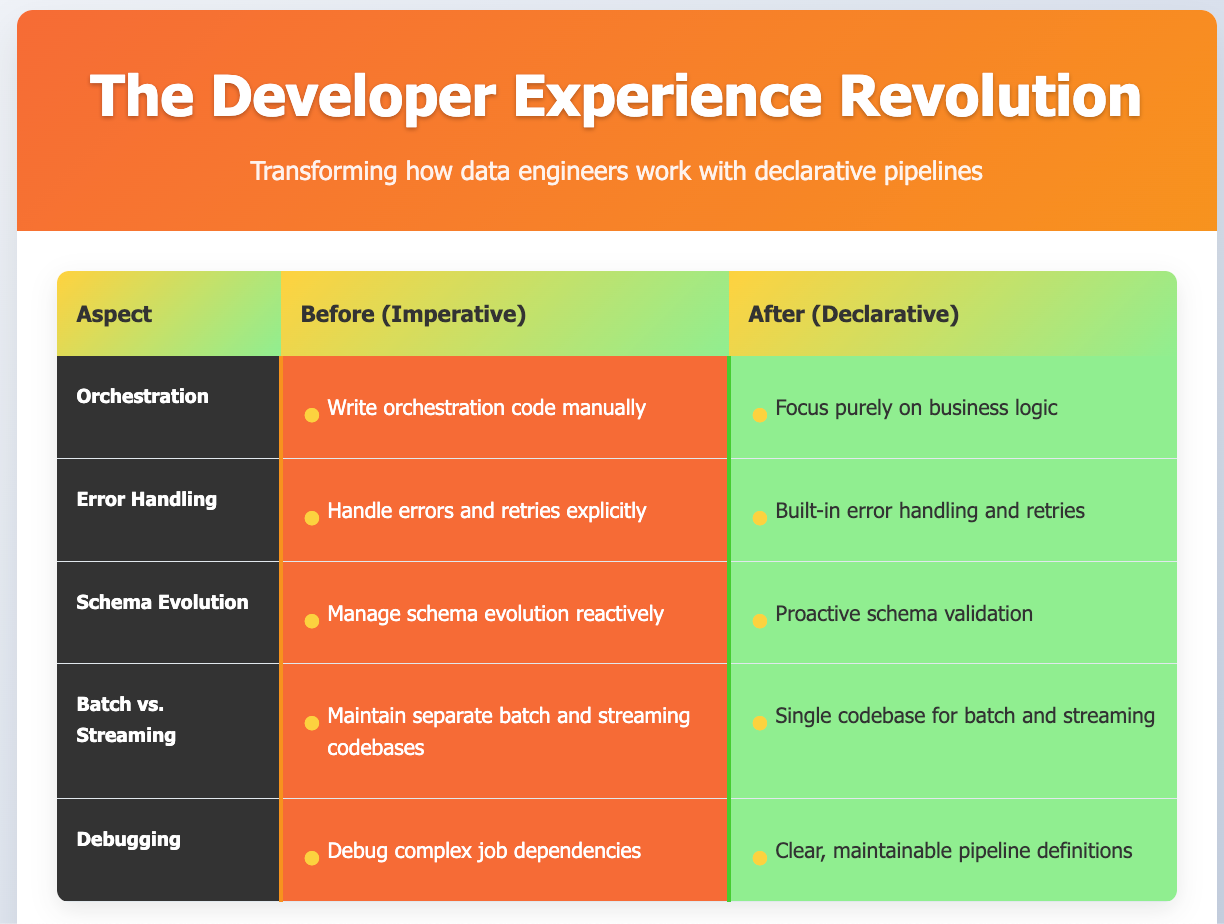
What's Next?
In Part 2 of this series, we'll dive deep into the performance implications of declarative pipelines, as you know, abstraction are leaky and can back fire. We'll explore:
How declarative approaches can actually improve performance through global optimization
Benchmark comparisons between imperative and declarative approaches
When declarative pipelines excel and when they might introduce overhead
The declarative pipeline revolution is just beginning. As Spark 4.1+ rolls out with this capability, we're likely to see a shift in how data engineering teams approach pipeline development, from complex orchestration to simple, maintainable declarations of intent.
Stay tuned for Part 2, where we'll uncover whether "declarative" means "slower" or if this abstraction can actually make your pipelines faster.
Hi,
I’m wondering if this is something you’ve started to implement in your production pipelines. We’ve typically chained notebooks together and while that introduced some overhead, developing in and debugging a notebook is very easy (or at the very least very familiar).
When it comes to comparing notebook based development/debugging to declarative pipelines, what has that transition looked like?