
Apache Spark on Kubernetes: From Manual Submissions to Operators - Part 1
A practitioner's guide to the Spark-on-Kubernetes toolbox and when to use each approach


We often get asked about how Spark and Kubernetes work together, as running Spark workloads efficiently in cloud-native environments has been an ongoing challenge for many practitioners and organizations.
As our motto goes, "pick the right tool to solve the problem," We’ve decided to dedicate this post to exploring the Spark on K8s toolbox. This exploration journey, from manual Spark job submissions to sophisticated Kubernetes operators, tells a fascinating story of automation, reliability, and the evolution of cloud-native data processing that we’ve witnessed firsthand through various projects and countless conversations with fellow data engineers.
The Dawn of Spark on Kubernetes
When Apache Spark 2.3 arrived in February 2018, it brought something revolutionary: experimental native Kubernetes support. For the first time, Spark could run directly on Kubernetes clusters without requiring separate cluster managers like YARN or Mesos (Which is already deprecated). This was a "huge leap forward" that opened the door to truly cloud-native big data processing.
However, early adopters quickly discovered that while technically possible, running Spark on Kubernetes felt clunky. Users had to manually execute spark-submit --master k8s://... commands for each job, monitor driver pods through logs, and handle failures manually. There was no higher-level Kubernetes object tracking Spark job lifecycles, making it difficult to manage jobs using standard Kubernetes tooling.
The fundamental problem was that Spark applications were "vastly different from that of other workloads on Kubernetes." While Kubernetes excelled at managing web services, workers, and other long-running applications, Spark jobs had complex distributed architectures with drivers and executors, dynamic resource allocation, and sophisticated failure scenarios.
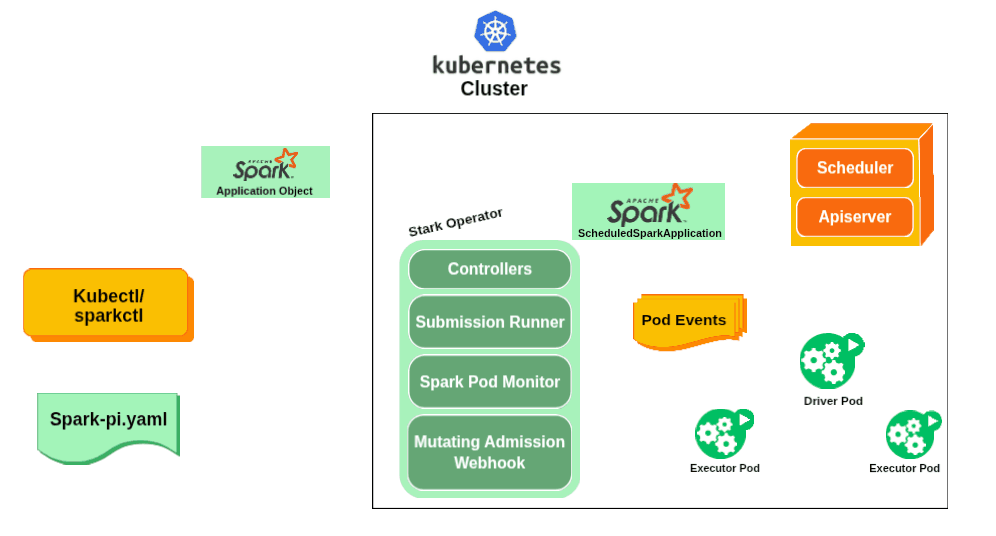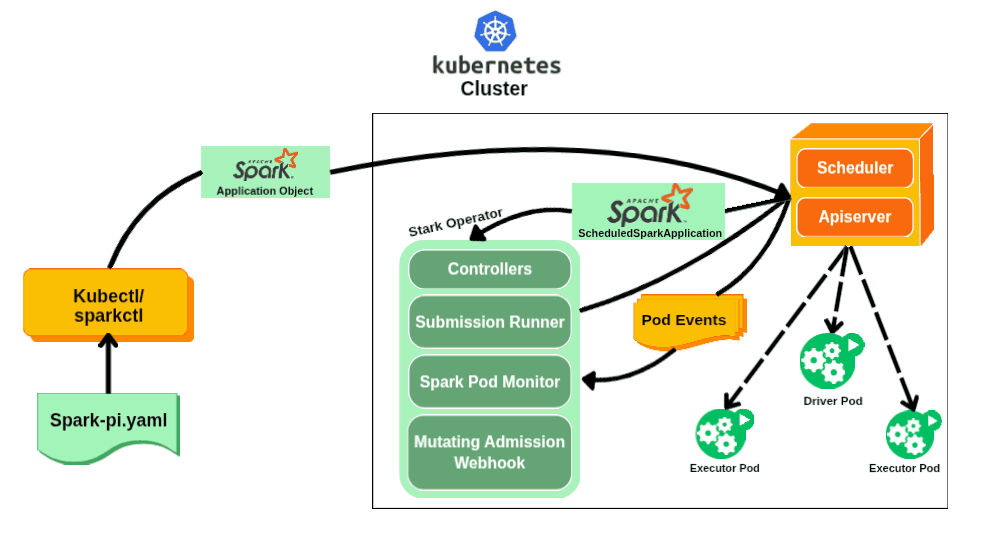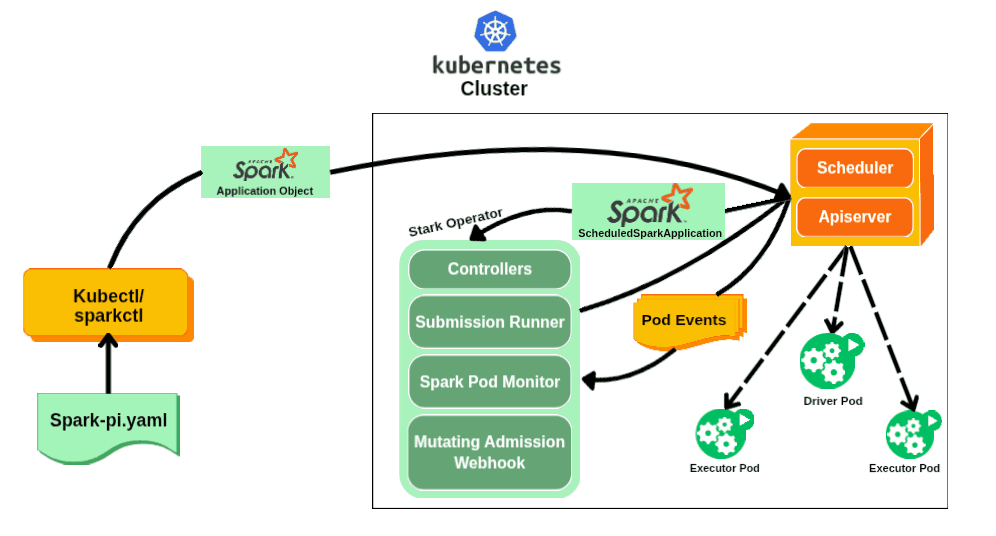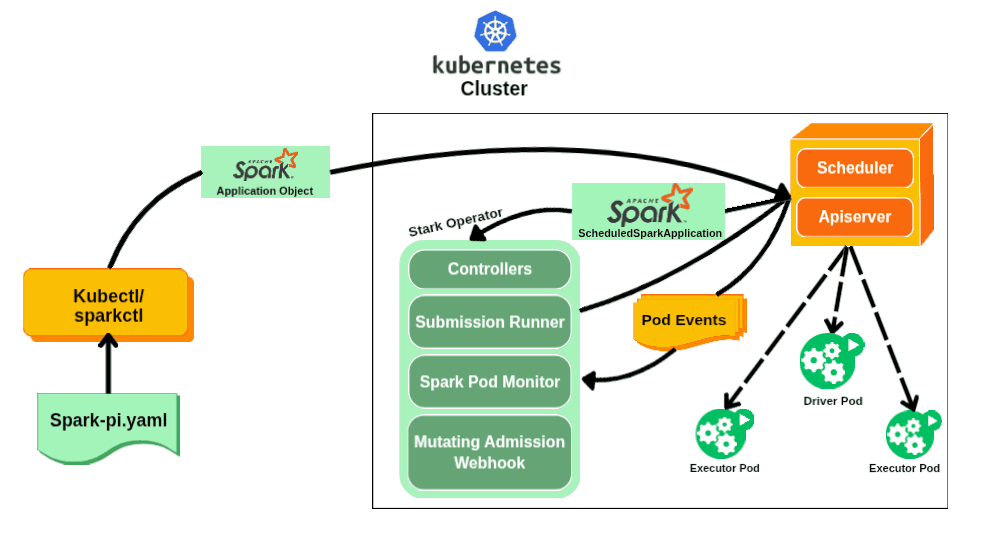
Enter the Spark Operator
Recognizing these limitations, engineers at Google began developing what would become the first Spark Operator around 2017. Their goal was ambitious: make Spark a first-class citizen on Kubernetes by bridging the gap between Spark's distributed computing model and Kubernetes' declarative management approach.
The original Google Spark Operator was open-sourced in late 2017, introducing Custom Resource Definitions (CRDs) that allowed users to define Spark jobs in YAML manifests, just like any other Kubernetes resource. Instead of imperative spark-submit commands, users could now declare their desired Spark application state and let the operator handle the rest.
The Kubeflow Era (2018-2023)
In 2018-2019, Google donated the Spark Operator to the Kubeflow project, ensuring community maintenance and evolution. This period saw rapid development:
Beta Release (January 2019): The operator reached beta status and became available on the GCP Marketplace
Feature Expansion: Support for PySpark, SparkR, scheduled jobs, and Prometheus integration
Production Adoption: Many organizations adopted it as the de facto standard for Spark on Kubernetes
The Kubeflow Spark Operator became battle-tested across diverse production environments, proving its value for automating Spark job lifecycles. However, by 2022-2023, development momentum slowed significantly. Key Google contributors moved on, and the project accumulated hundreds of open issues with infrequent releases.
The Apache Renaissance (2024-2025)
Rather than trying to revive the aging Kubeflow operator, the Apache Spark community made a bold decision: build a new operator from scratch under Apache Software Foundation governance. This wasn't just about changing ownership, it was about creating a modern, forward-looking solution designed for Spark's future.
In May 2025, the Apache Spark Kubernetes Operator launched as an official subproject, supporting Spark 3.5+ and modern Kubernetes features. The rapid release cycle (v0.1.0 in early May, v0.2.0 weeks later) signaled a serious commitment from the Spark community.
Why Spark Operators Are Essential
To understand why operators became necessary, consider the difference between imperative and declarative approaches:
The Imperative Struggle
Without an operator, running Spark on Kubernetes requires:
Manual
spark-submitexecution for each jobCustom scripting for monitoring and failure handling
External tools for scheduling recurring jobs
No unified view of Spark applications in Kubernetes
Error-prone manual intervention for retries and cleanup
This imperative model works for occasional jobs but breaks down at scale. A DevOps engineer might write bash loops to submit jobs and check their status, hardly the robust, automated approach that modern data platforms require.
The Declarative Advantage
Spark Operators transform this experience by enabling:
Declarative Job Management: Define Spark jobs in YAML and let the operator ensure they run to completion
Automated Resilience: Built-in retry policies, failure handling, and restart capabilities
Native Kubernetes Integration: Spark applications become first-class Kubernetes resources, manageable via
kubectlEnhanced Observability: Automatic metrics export to Prometheus and detailed status tracking
GitOps Compatibility: Version-controlled SparkApplication manifests enable reproducible deployments
The Modern Landscape: Two Operators, Different Strengths
Today's Spark-on-Kubernetes ecosystem features two primary operators, each with distinct advantages:
Kubeflow Spark Operator: The Veteran
Strengths:
Battle-tested in production environments
Supports Spark 2.3+ (including legacy versions)
Rich feature set including scheduled jobs and metrics integration
Extensive community knowledge and documentation
Mature mutating webhook for advanced pod customization
Limitations:
Development has stagnated (minimal releases since 2022)
Still in beta status with no stable 1.0 release
Limited support for newer Spark features like Spark Connect
Legacy design decisions from early Spark-on-K8s days
Apache Spark Operator: The Next Generation
Strengths:
Official Apache project with active development
Modern architecture designed for Spark 3.5+
First-class Spark Connect support
New SparkCluster CRD for persistent Spark clusters
Aligned with Spark's roadmap and release cycle
Limitations:
Very new (0.x releases) with a limited production track record
Requires Spark 3.5+ (no legacy support)
Smaller community ecosystem compared to the Kubeflow operator
Some features are still maturing
Beyond Operators: Evaluating Alternatives
While Spark Operators provide compelling benefits, they're not the only approach to running Spark on Kubernetes. Here's how they compare to alternatives:
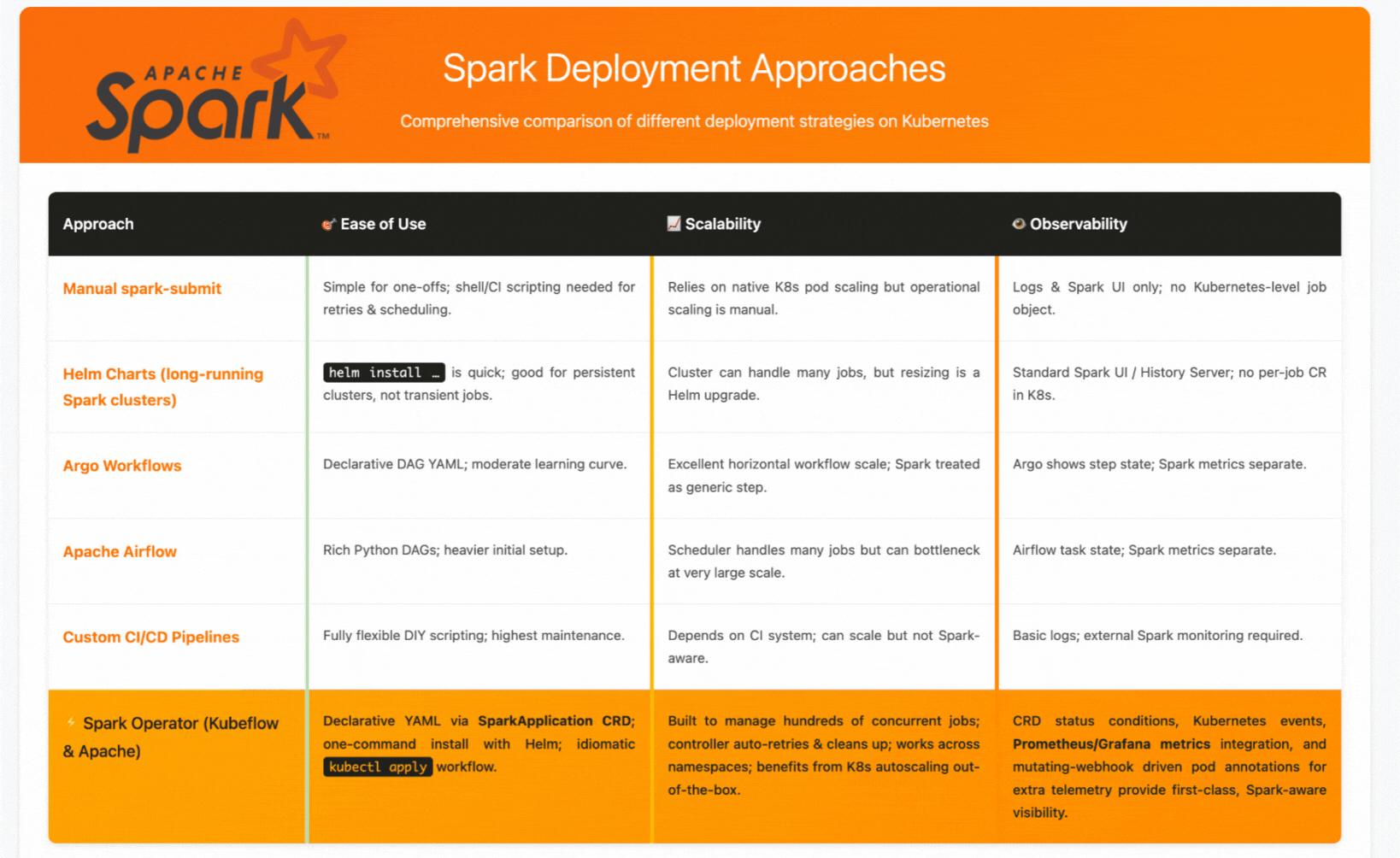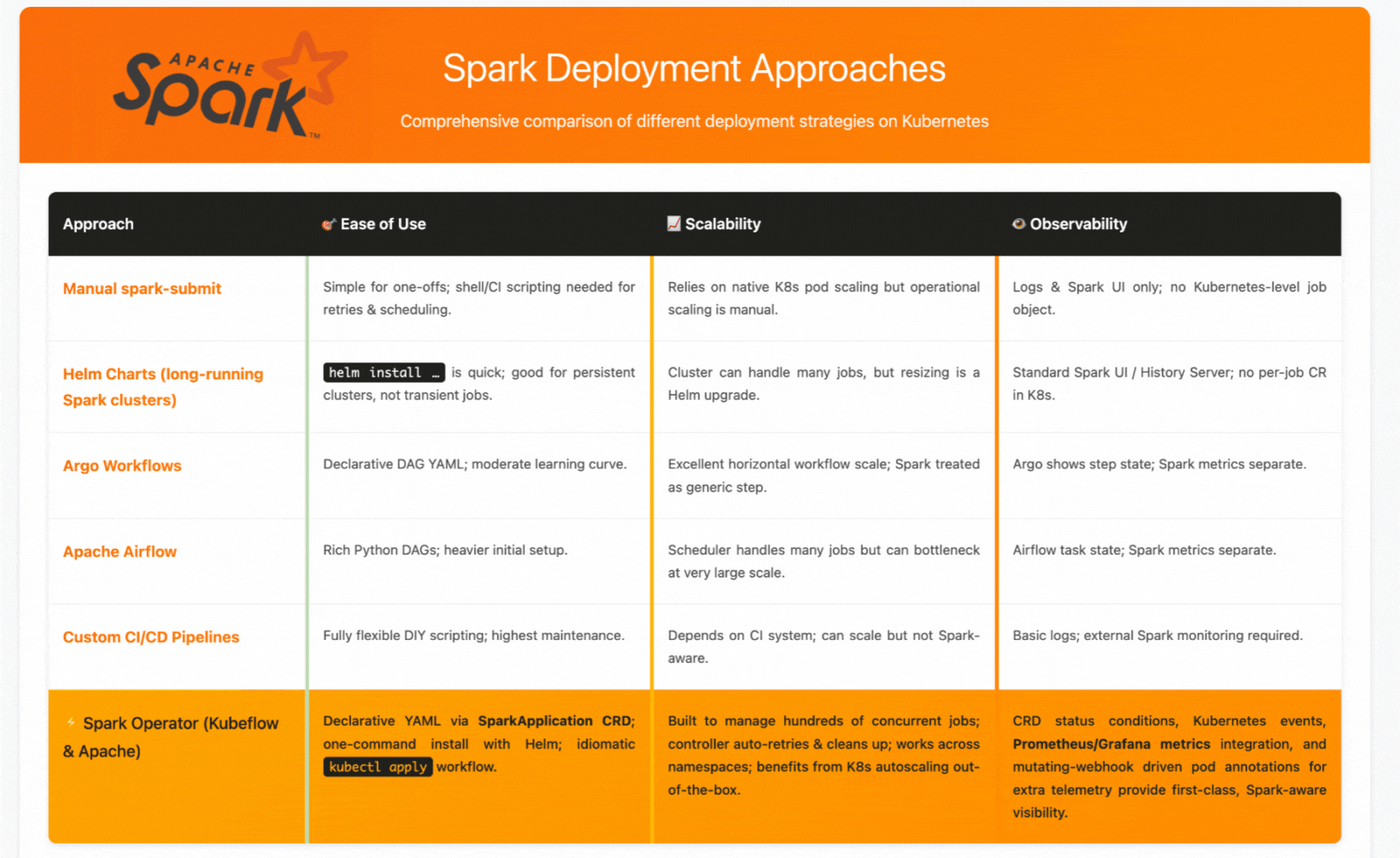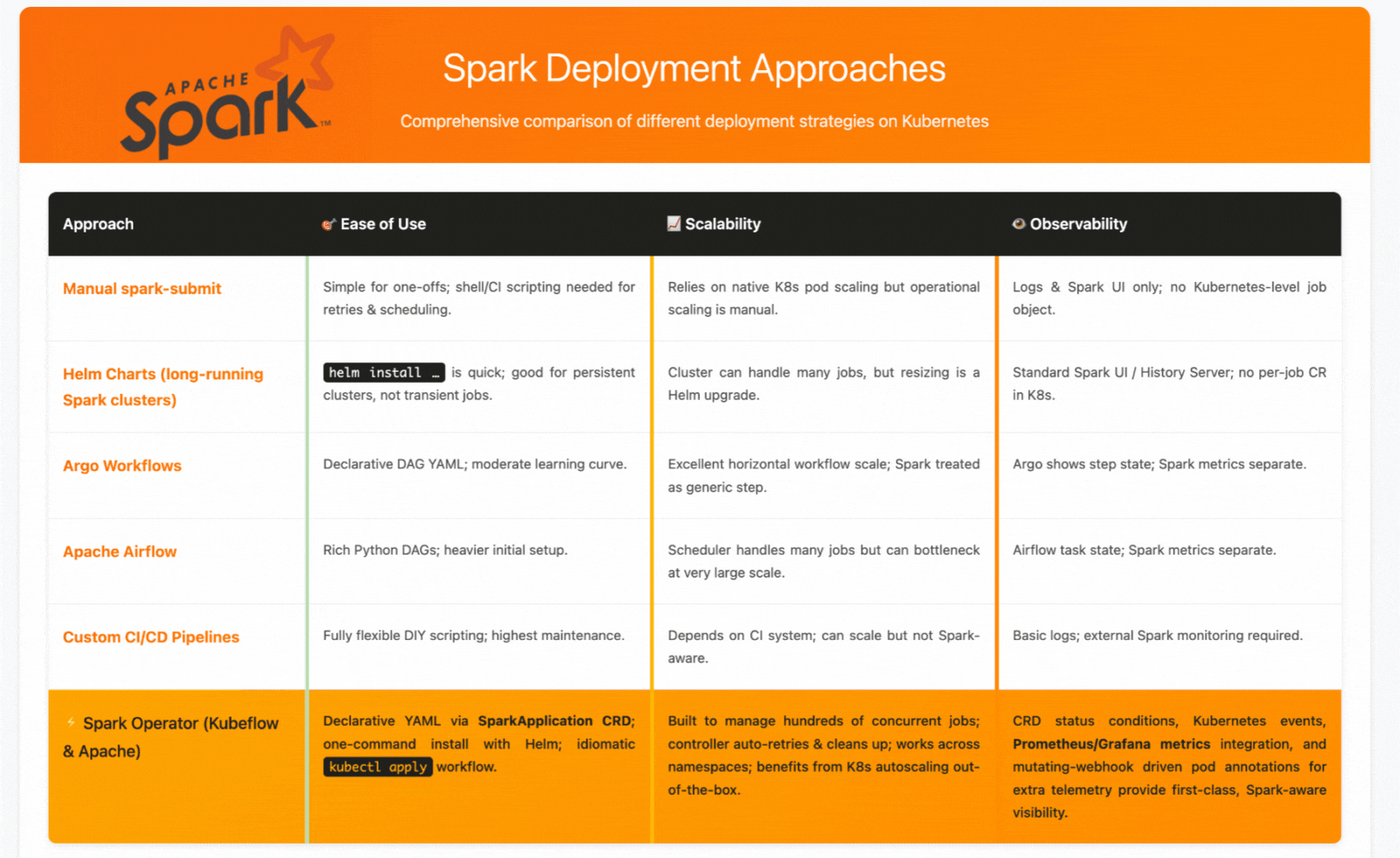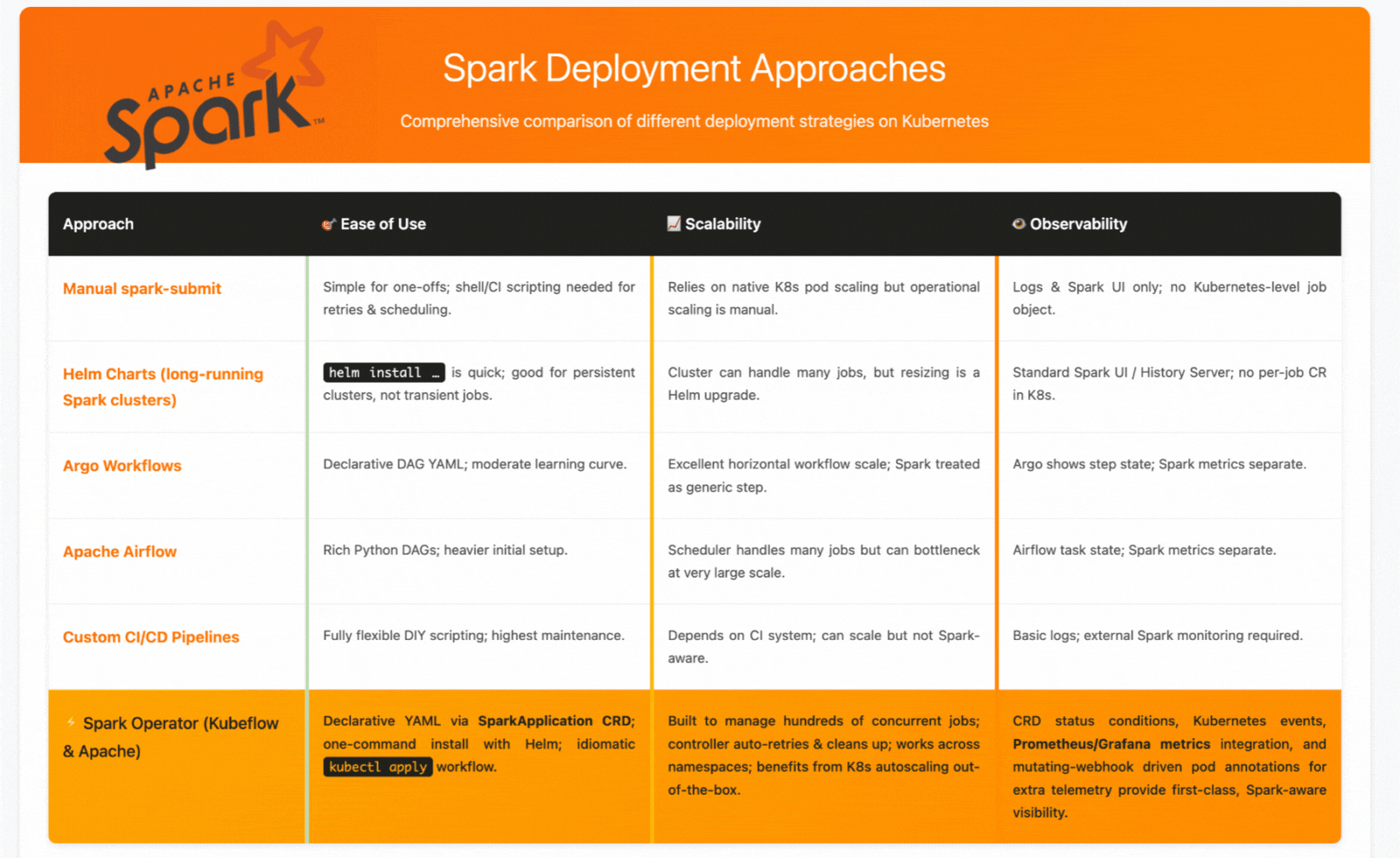
When to Choose Each Approach
Choose manual spark-submit for one-off analysis or simple testing scenarios where automation isn't critical.
Choose Helm charts when you need persistent, shared Spark clusters for interactive analysis or multi-user environments.
Choose workflow orchestrators (Argo/Airflow) for complex data pipelines with multiple tools and dependencies, where Spark is one component in a larger workflow.
Choose Spark Operators when you want Kubernetes-native Spark job management with automated lifecycle handling, retry policies, and integrated monitoring—essentially when you want Spark to feel like a natural Kubernetes workload.
Coming Up Next
In Part 2 of this series, we'll dive deep into the performance and operational considerations of running Spark Operators in production environments, including resource efficiency, reliability improvements, and observability enhancements.
Stay tuned!