
Understanding Apache Spark Shuffle for Better Performance
Shuffle in Apache Spark: How to Minimize Its Impact and Boost Performance


Performance bottlenecks in Apache Spark often times correlated to shuffle operations which occur implicitly or explicitly by the user. In this post we will try to introduce and simplify this special operation in order to help you use it more wisely within your Spark programs.

Apache Spark Shuffle
Shuffle in Apache Spark occurs when data is exchanged between partitions across different nodes, typically during operations like groupBy, join, and reduceByKey.
This process involves rearranging and redistributing data, which can be costly in terms of network I/O, memory, and execution time.
Efficient shuffle management is crucial for optimizing performance, as excessive shuffling can slow down Spark jobs and lead to out-of-memory errors. To fully understand shuffle, we first need to understand the concept of partitions in Spark.
What are Spark partitions?
In the big data regime, the data is too large to fit into a single machine, so we must break it down into smaller chunks. These chunks are called partitions.
In Spark, partitions represent a logical division of data within a DataFrame, defining how data is distributed across executors.
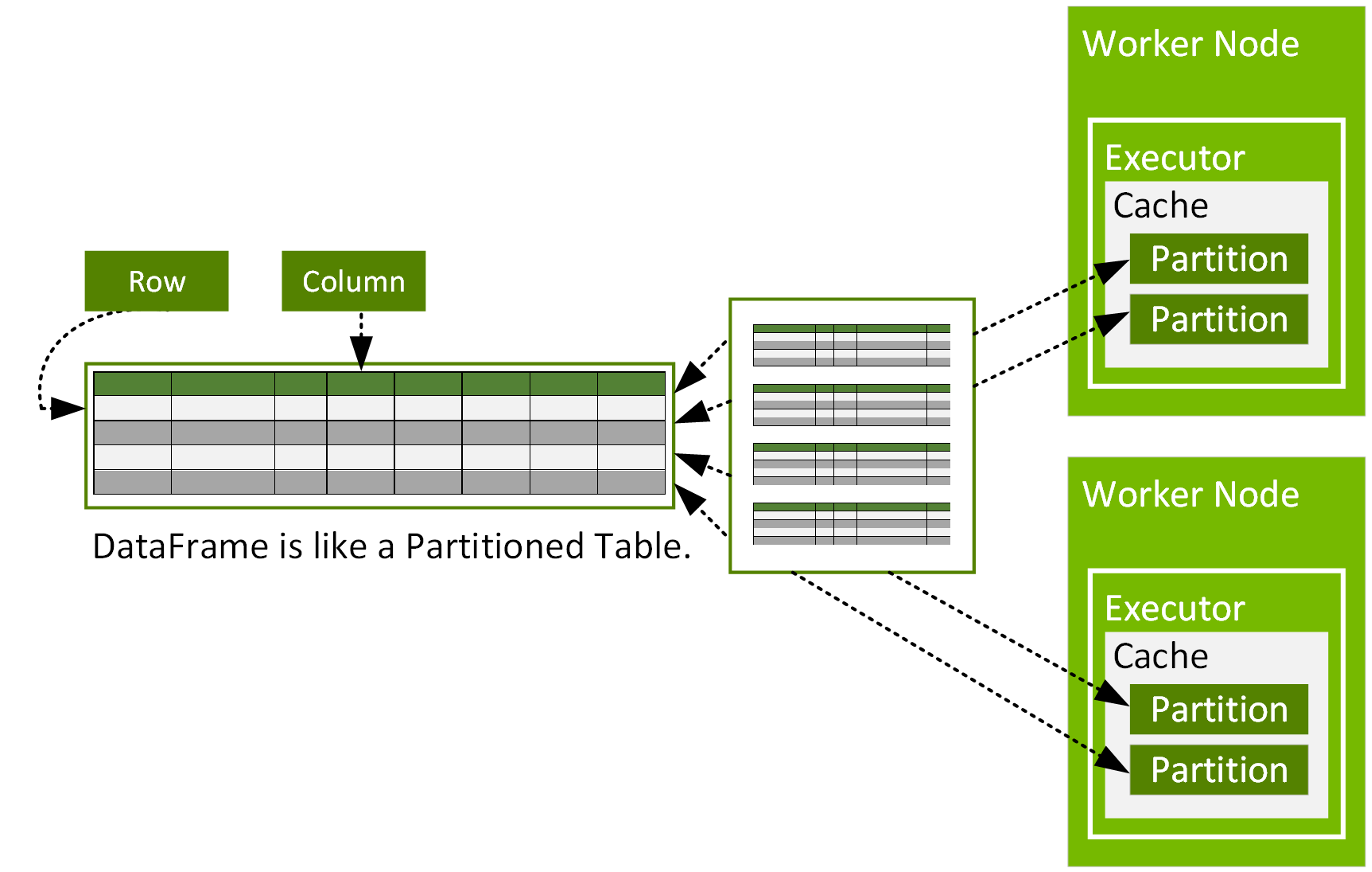
A partition exists only within the execution context of Spark and may change during processing based on certain operations performed in the program. Spark splits large datasets into multiple partitions, where each partition processed by a different worker node(executor) in the cluster.
More partitions improve parallelism, but too many partitions can introduce overhead. Partitions are stored in memory when possible but spill to disk if they don’t fit, which negatively impacts performance.
Since each partition is processed by a specific executor, it would be ideal for every executor to handle an equal amount of data for balanced workload distribution. However, this is not always the case, as data distribution varies depending on the operation performed. Sometimes, data is evenly distributed across partitions, while other times, we see significant variance in the amount of data assigned to each partition.
So what is shuffle?
The operation of redistributing data across different partitions is called Shuffle.
Why does Spark shuffle data?
Spark shuffles data for certain operations that requires redistributing data between partitions. For example, when Spark needs to group, join, or reorganize data that isn’t already in the same machine.
When does shuffle occur?
Spark shuffles data for certain operations that requires redistributing data between partitions:
groupBy() followed by agg() — Requires shuffle to move all records of the same category into the same partition.
orderBy() or sort() — Forces a full shuffle because Spark needs to globally sort records.
Join (where broadcast is impossible) — Spark shuffles data to align matching keys. Always try to use broadcast join where possible to avoid shuffle.
repartition(n) — Full shuffle of data evenly across n partitions.
repartition(column) — Full shuffle of data across partitions according to specified column.
partitionBy(column) (used in window functions) — If data isn’t already partitioned by column, Spark shuffles it.
Why Do We Care About Shuffle in Spark?
Shuffle is one of the biggest performance bottlenecks in Apache Spark. While it’s necessary for some operations, it can significantly impact job execution time and resource consumption:
Shuffle is Expensive
Network Transfer → Data moves across nodes, causing latency.
Disk I/O → Intermediate shuffle files are written and read from disk.
CPU Overhead → Serialization, deserialization, and data sorting add processing time.


Unoptimized Shuffle Causes Bottlenecks
If some partitions receive more data than others (data skew — explained in details later), certain tasks take much longer to finish, delaying the entire job.
Shuffle can result in uneven workload distribution, leading to idle cores.
Shuffle Can Lead to Out of Memory (OOM) Errors
Large shuffle operations consume a lot of memory for sorting and buffering data.
If data doesn’t fit in memory, Spark spills to disk, making it even slower.
What is Data Skew?
As mentioned earlier, data skew is a situation where some partitions receive significantly more data than others. Let’s try to break it down to understand how this could happen.
Imagine that we have a dataframe containg a column named pet, representing the type of pet and each row represents a value of pet type recorded per family. We want to understand how many families grow each type of pet. Using Spark we will need to perform a group by operation in combination with count. The group by will create a shuffle dividing the values to different partitions per pet type, in order to enable the count, as can be seen in the below photo.
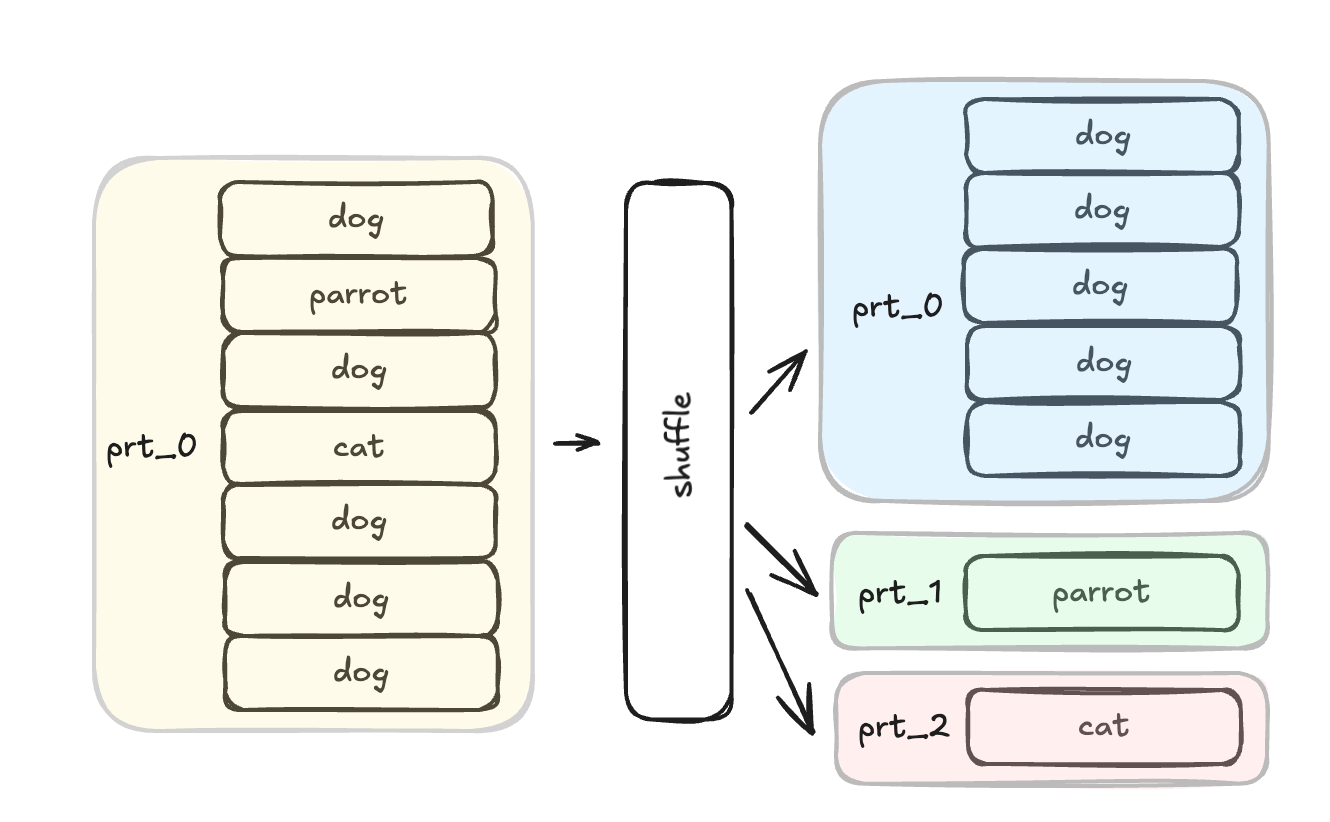
As seen in the example above, the result dataframe will have 3 partitions (3 different pet types), where one partition (dog) is significantly larger than all other ones.
Now that each partition holds all relevant data for each pet, the count calculation can be performed. However, since each partition is processed by a different executor, one executor may end up with significantly more work than the others.
This imbalance is known as Data Skew—an uneven distribution of data across partitions. Data skew can occur as a result of the shuffle process, so it’s important to carefully design operations and monitor the Spark UI to detect and minimize these issues.
Data skew can severely impact performance, leading to lagging tasks, prolonged execution times, and out-of-memory errors that may even cause the program to crash.
One effective way to address this issue is salting, which involves adding a random suffix or prefix to keys before shuffling. This forces Spark to distribute data more evenly across partitions, preventing workload imbalances. Once processing is complete, the salt can be removed, ensuring efficient aggregation while improving overall performance.
How To Minimize Shuffle Impact?
✔ Broadcast Join — Use broadcast() for small DataFrames instead of shuffling large datasets in joins. Using broadcast removes the need for shuffle.
✔ Coalesce — Use coalesce() instead of repartition() when reducing partitions to avoid full shuffle. Coalesce does not use full shuffle, though pay attention that it can cause data skew.
✔ Correct Partitioning — Partition your data wisely to reduce unnecessary movement.
✔ Monitoring — Monitor Spark UI to detect shuffle bottlenecks (check shuffle read/write metrics).
In conclusion — It’s important to be aware of the query plan in the Spark UI, notice shuffle operations that exist in our program and try to minimize or optimize them in order to significantly improve our Spark jobs.
 | A guest post by
|