
Unpacking Trino's Query Execution: From SQL to Splits
Understanding How Your SQL Query Flows Through Trino's Distributed Architecture

Trino is purpose-built for SQL analytics, with an execution engine designed to optimize complex queries across distributed data sources. As a SQL-first platform, it transforms declarative queries into highly optimized execution plans behind the scenes.
I’ve covered Spark quite a lot, and I want to dedicate this post to Trino, which will enable us to compare them in the future and guide us in choosing the right tool to solve the problem.
Many Trino users simply write their SQL and enjoy fast results, without necessarily exploring how Trino efficiently dissects and distributes that work across a distributed computing environment.
Let's unpack Trino's hierarchical execution structure to see how your SQL query flows from a high-level statement down to individual CPU cores, revealing the optimization process that happens along the way.

Key Characteristics of Trino's Execution Model
Understanding the fundamental characteristics of Trino helps leverage it effectively:
1. Eager Execution
Once a query is submitted and planned, Trino operates eagerly. Data starts flowing through the Stages pipeline as soon as upstream Tasks produce output.
2. SQL-First Programming Model
Trino uses a SQL-first approach with upfront query planning and optimization, primarily using a declarative SQL interface.
3. In-Memory Data Handling
Trino aims to keep intermediate data in memory and stream it between workers, though it can spill to disk under memory pressure.
4. Dynamic Resource Management
Trino features dynamic resource allocation controlled by the coordinator, which adapts to query needs in real-time.
5. Interactive Query Optimization
Trino is optimized for interactive, ad-hoc SQL queries across disparate data sources, with a focus on low latency.
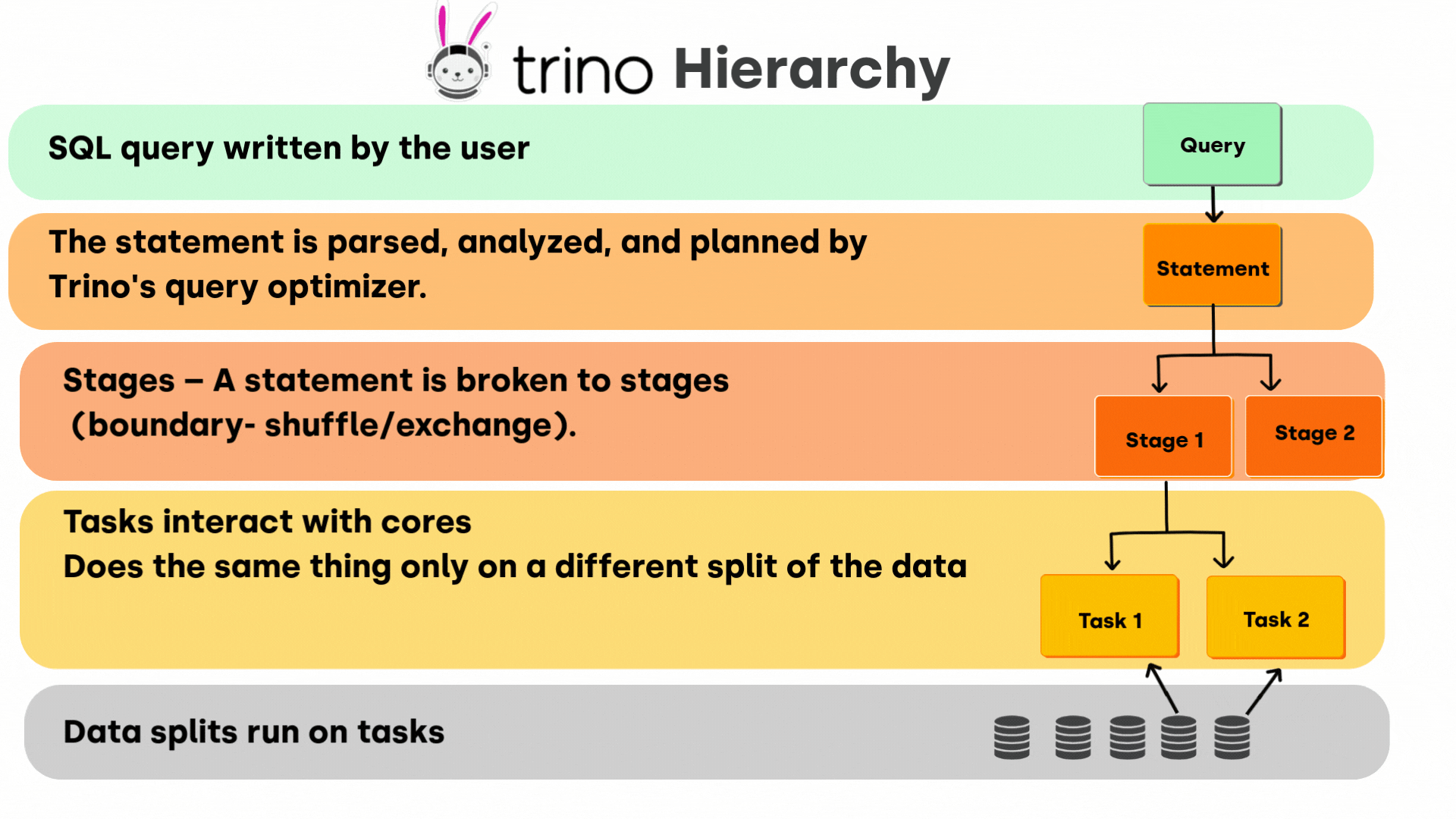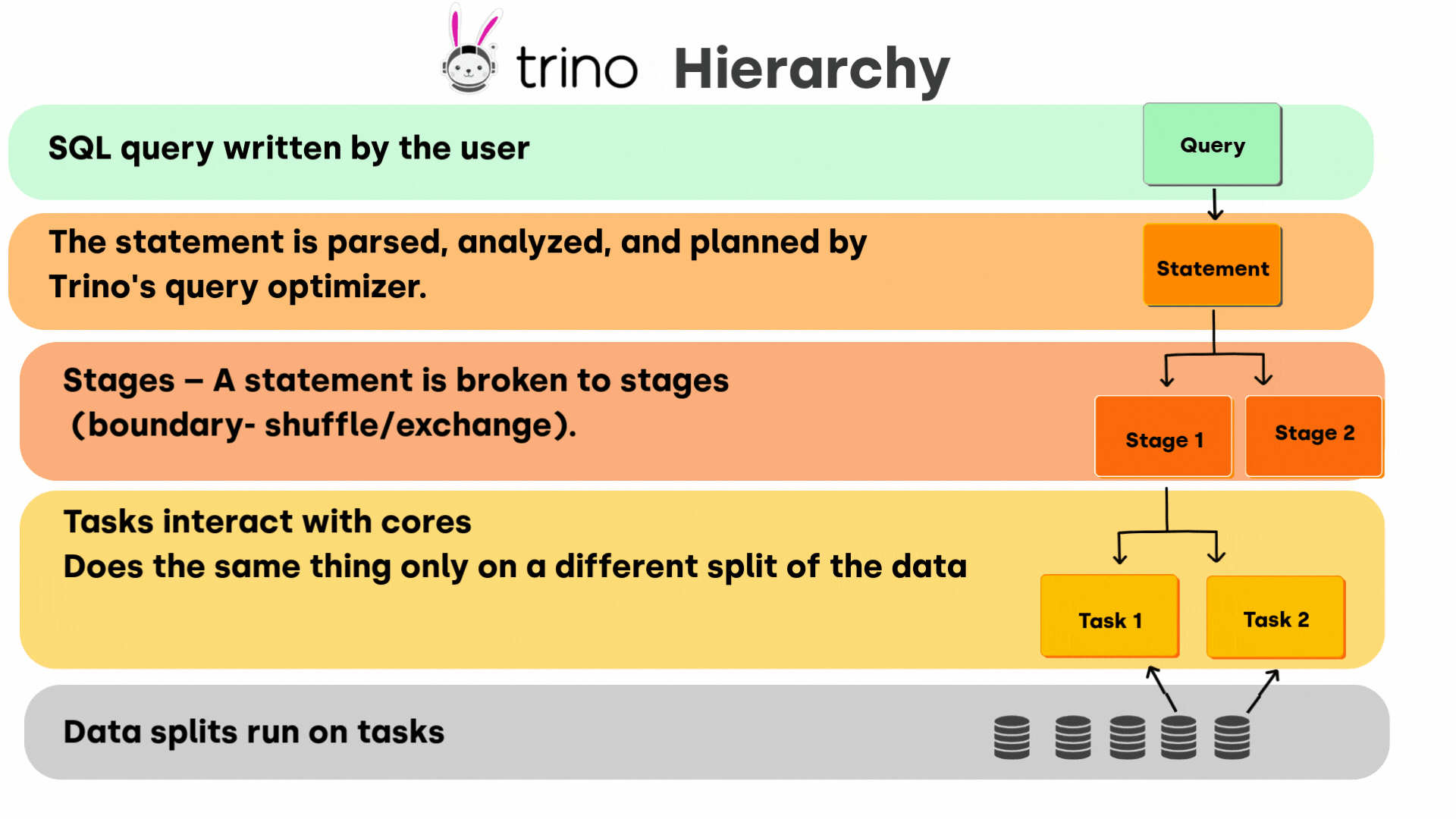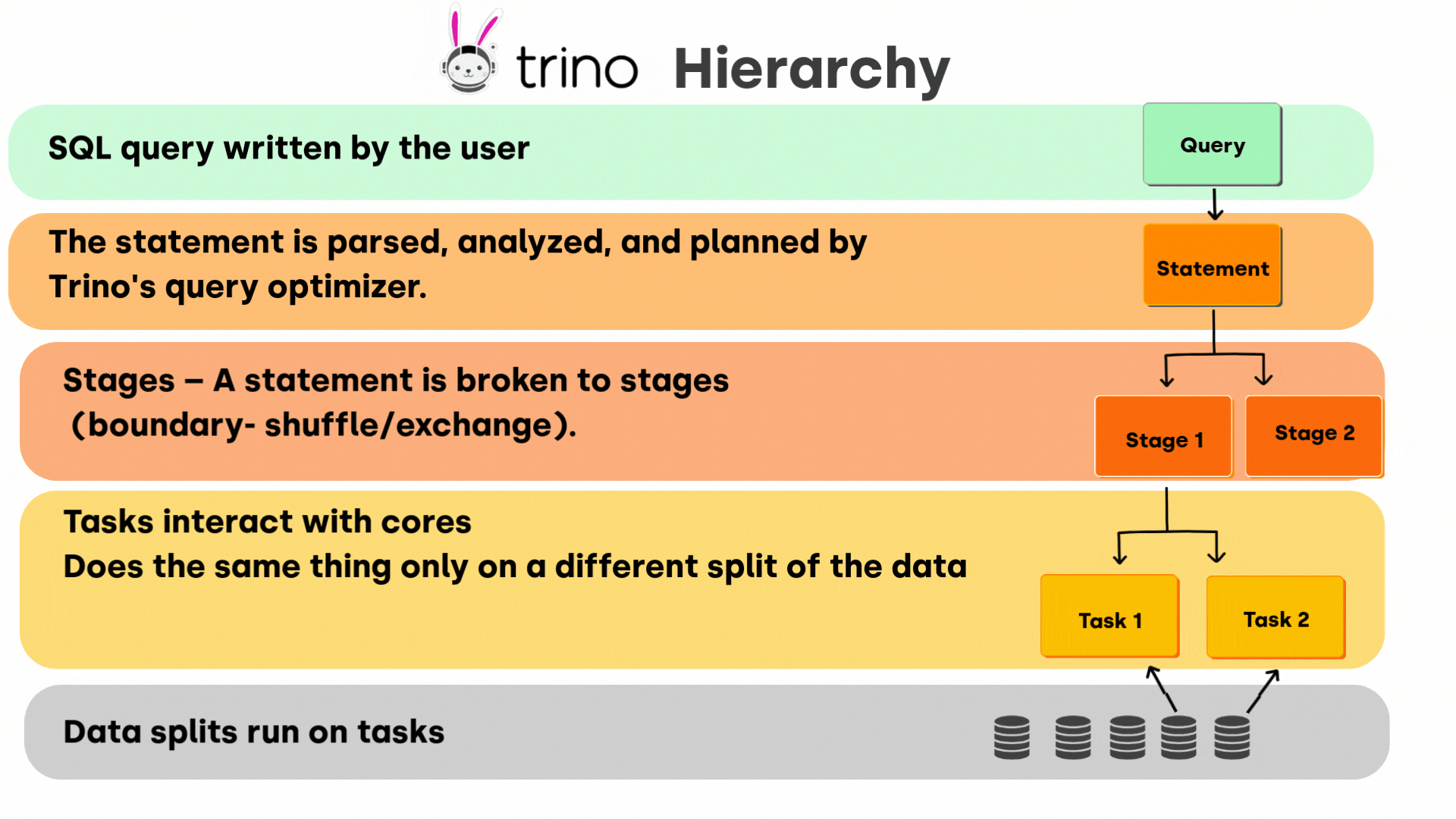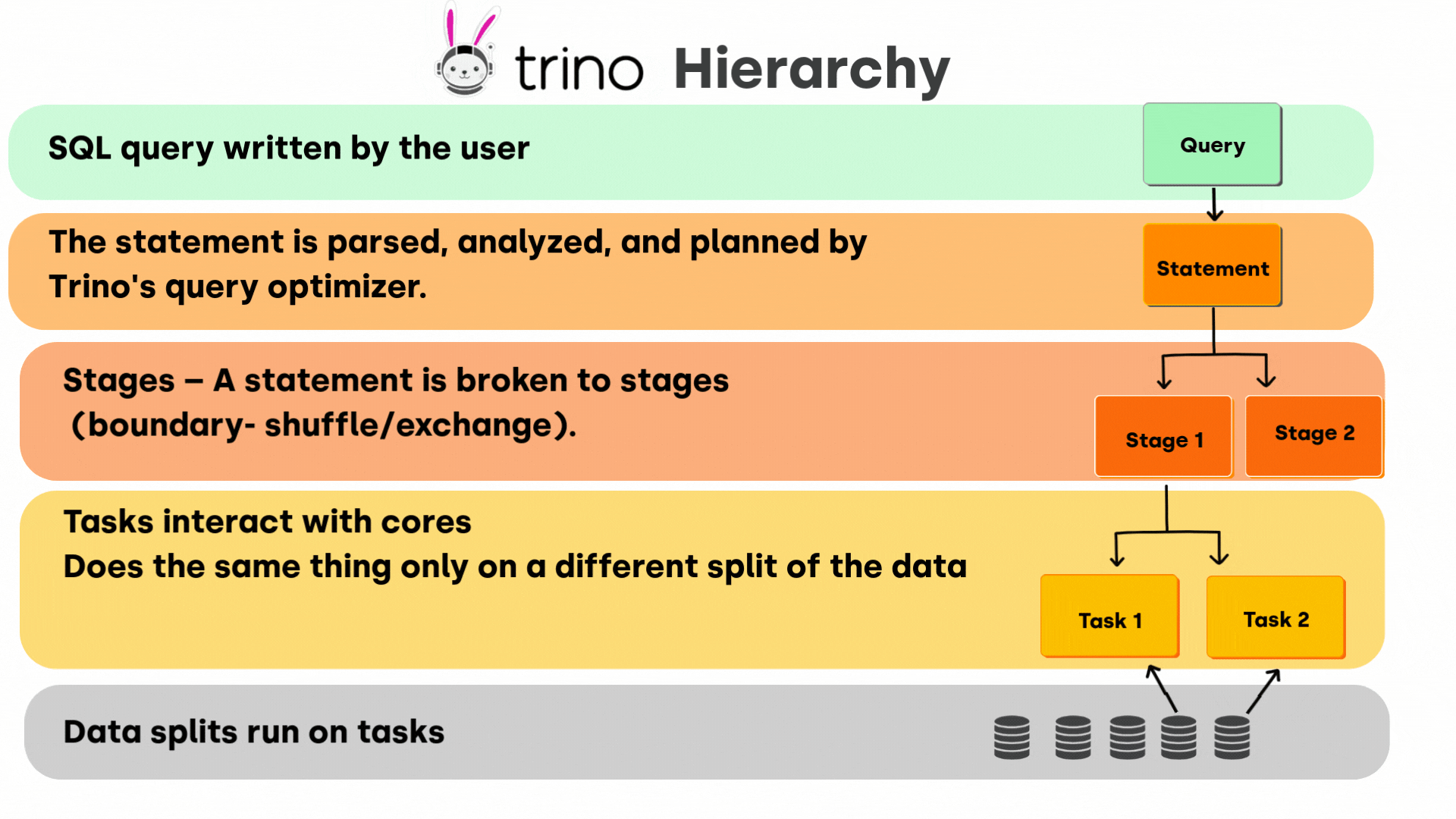
The Trino Execution Hierarchy Explained
As all compute engines Trino's execution model follows a clear hierarchy, breaking complex SQL queries into progressively smaller units that optimize parallel processing:
Query: The User's Request
At the highest level is the Query – the SQL statement you submit to the Trino Coordinator. This is the complete unit of work from the user's perspective. The Coordinator receives the SQL query, parses it, analyzes it, and generates an optimized distributed query plan.
Statement: SQL Processing Path
Each Query in Trino contains exactly one Statement. The statement is parsed, analyzed, and planned by Trino's query optimizer. Trino begins executing as soon as you submit your query.
During this phase, Trino performs:
SQL parsing
Query analysis
Logical planning
Query optimization
Physical planning
Stage: Phases of the Execution Plan
The Coordinator breaks the distributed query plan into Stages. A Stage represents a phase of the query execution plan that can be executed together. Stages consume data from previous stages (or directly from data sources) and produce intermediate data for subsequent stages. The boundaries between Stages are typically defined by operations requiring data redistribution across the cluster, known as Exchanges (shuffle).
Common operations that necessitate stage boundaries include (similar to Spark):
JOINs (redistributing data based on join keys)
Aggregations (GROUP BY clauses, redistributing data by grouping keys)
UNION ALL (gathering data from different sources/subqueries)
ORDER BY (when not performed within a source)
Data flows between stages, often being repartitioned (shuffled) during the Exchange operation.
Task: Work Units on Worker Nodes
Each Stage is implemented by one or more Tasks running on Trino Worker nodes. A Task is a specific piece of the Stage's logic assigned to a Worker. For instance, in a stage performing a GROUP BY aggregation, multiple Tasks might run in parallel, each handling a subset of the grouping keys. Tasks within a stage run the same code but operate on different portions of the data.
The number of Tasks in a stage determines its parallelism level. Tasks pull data from previous stages (or data sources via Splits) and push results to the next stage.
Split: The Smallest Unit of Data
At the lowest level, Tasks operate on Splits. A Split represents a chunk of data from the underlying data source that can be processed independently. For a Hive table stored in ORC or Parquet files, a Split might correspond to a portion of a file or an entire small file. Connectors are responsible for enumerating the Splits for a given table scan.
A single Task can process one or more Splits sequentially. The Coordinator assigns Splits to available Tasks within the appropriate Stage.
Performance Implications for Trino Optimization
This execution hierarchy directly impacts Trino performance in several ways:
Queries and Planning
Query Complexity: More complex SQL queries generate more complex execution plans with more stages, potentially leading to more data exchange operations.
Statistics and Cost Models: Trino relies heavily on statistics for query planning. Missing or inaccurate statistics can lead to suboptimal execution plans.
Stages and Data Exchange
Join Ordering: The way Trino orders join operations significantly impacts performance, as it determines how data flows between stages.
Broadcast vs. Distributed Joins: Small tables can be broadcast to avoid costly redistributions.
Predicate Pushdown: Trino aggressively pushes predicates down to data sources, reducing unnecessary data reading.
Tasks, Splits & Resource Management
Task Concurrency: Trino's performance scales with the number of concurrent tasks that can run on your cluster (configured by task.concurrency settings).
Memory Management: Each task has memory allocations that need to be tuned based on your workload characteristics.
Worker Distribution: Evenly distributing tasks across workers prevents hotspots and resource contention.
Split Management: Uneven Split sizes or data skew can cause specific Tasks to run much longer than others, delaying the entire Stage.

When to Use Trino
Trino excels in specific scenarios that align with its design philosophy:
Interactive Analytics: When you need sub-second or few-second response times for business intelligence (BI) queries
Federated Queries: When connecting to multiple data sources (Hive, Postgres, MongoDB, etc.) in a single SQL statement
Data Lake Queries: For analyzing diverse data formats (Parquet, ORC, Avro) stored in object stores or HDFS
Advanced SQL: When leveraging complex SQL features like window functions, sophisticated joins, and specialized aggregations
Concurrent Workloads: When supporting many analysts running different queries simultaneously
Already Processed Data: When data has already been transformed and you primarily need fast query capabilities
Conclusion: Leveraging Your Knowledge of Trino's Execution Model
Understanding Trino's execution hierarchy, from Queries down to Splits, transforms how you approach development, debugging, and optimization of distributed SQL queries. This knowledge empowers you to:
Write Smarter SQL: Anticipate how your SQL constructs will translate into Stages and Exchanges
Debug Performance Issues Methodically: Isolate bottlenecks to specific Queries, Stages, Tasks, or even data Splits, rather than guessing at configuration parameters
Optimize Cluster Resources: Make informed decisions about worker node sizing, concurrency settings, and source data layouts
Communicate Effectively: Use precise terminology (Stages, Tasks, Splits, Exchanges) when discussing performance issues
Rather than treating Trino as a black box that occasionally needs configuration tweaks, you can approach optimization methodically by understanding the relationships between your SQL, the resulting execution plan, and the resources available in your cluster.
Whether you're querying gigabytes or petabytes of data across multiple data sources, this foundation in Trino's execution model will serve you well as you build and scale data processing applications across your organization.