
Why Big Data Engineers Are Missing Out on the AI Code Revolution - Part 1
The Ultimate Paradox of 2025: Big Data Engineers Top the Charts Yet Fall Behind

As someone who has spent more than 15 years in data science and machine learning engineering, I've observed an interesting paradox in today's tech landscape. This post explores a less technical but deeply important trend affecting data professionals.
Here's the mind-bending irony of today's tech landscape: According to the World Economic Forum's Future of Jobs Report 2025, big data specialists are the #1 fastest-growing profession worldwide, outranking even AI specialists. Yet these same in-demand professionals are being left behind in the very AI revolution they're supposed to be leading.
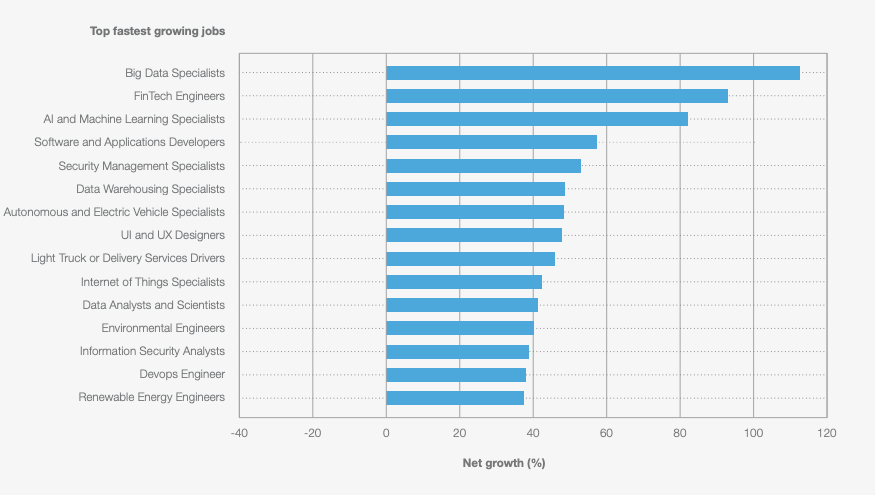
Why this explosive growth in Data Engineering?
The answer is fundamental: the sheer volume and complexity of data generated globally are exploding. Every AI initiative, every business decision, and every operational improvement hinges on a reliable, high-quality data infrastructure. Data Engineers are the crucial architects who build and maintain the robust pipelines, scalable warehouses, and performant lakes required to make this data usable. They are the essential bedrock on which the entire data and AI ecosystem is built. Without them, the promise of AI remains just that – a promise, starved of the necessary fuel.
But here lies the truly astonishing paradox:
These indispensable professionals, the very foundation builders of our data-driven future, are finding themselves strangely sidelined in the AI productivity revolution sweeping through the rest of the tech world.
While developers across nearly every other discipline are experiencing unprecedented productivity gains from sophisticated AI coding tools integrated directly into their workflows, the engineers responsible for the data foundations powering our AI future are watching from the sidelines.
They use the data to enable AI, but the AI struggles to empower them in coding their own complex, critical data infrastructure tasks. They are unable to fully participate in the coding renaissance experienced elsewhere.
Why?
Because current AI coding tools are missing something critical: infrastructure context. The same big data engineers who command top salaries and have companies desperately competing for their talents find themselves deeply frustrated by AI assistants that generate code that looks syntactically perfect, passes basic unit tests, but performs terribly, causes massive cost overruns, or introduces dangerous instability in real-world production environments.
The Three Contexts That Matter in Big Data Engineering
For code to be truly effective in a big data environment, it needs to account for three critical contexts:
Business context (what your application is doing)
Data context (what your database or lake actually stores)
Infrastructure context (how your big data engine works in production)

While general software engineering certainly can leverage LLM’s without proper context as long as the code will complie, big data engineering stands uniquely apart because of its extreme, non-negotiable sensitivity to infrastructure context. A lack of awareness here doesn't just mean slightly less efficient code; it can mean catastrophic performance failures, resource exhaustion, or cloud bills that bankrupt departments.
This context gap isn't just a theoretical problem for data engineers; it has severe, tangible consequences.
Next week, in Part 2 of this series, we will illustrate this profound disconnect with concrete, eye-opening examples. We will present actual code snippets generated by popular AI coding assistants for typical big data tasks and walk you through exactly why these seemingly correct suggestions would fail spectacularly, cost a fortune, or cause significant performance regressions when deployed to a real big data infrastructure, all because the AI lacks crucial infrastructure context.
Stay tuned!