
Introducing Spark Connect – What It Is and Why It Matters - Part 1
Exploring the New Client-Server Architecture in Apache Spark 4.0

This year, Apache Spark 4.0 is set to be released, bringing one of its most anticipated features: Spark Connect.
This enhancement makes Spark more flexible and developer friendly by introducing a client-server protocol that separates Spark applications from the execution engine. The result is a more stable, scalable, and accessible Spark experience.
Spark Connect is expected to have a significant impact on performance, which is why we believe it deserves a two part blog series to cover its full potential.
For years, developers have faced challenges running Spark applications efficiently. Managing dependencies, dealing with cluster crashes due to shared workloads, and struggling with real-time debugging have all been common pain points. Spark Connect aims to change that.1.

What is Spark Connect?
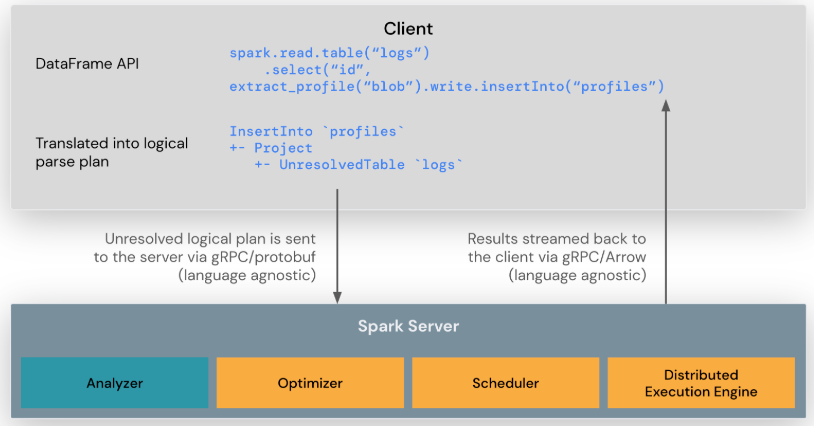
At its core, Spark Connect is a lightweight client-server architecture that allows your application to connect to Spark remotely. Traditionally, Spark applications and the Spark driver ran in the same process, making them tightly coupled. With Spark Connect, your application acts as a thin client that sends commands to a remote Spark driver over a network.
Imagine writing Spark code on your laptop or inside a cloud based notebook and seamlessly connecting to a Spark cluster without needing to run the entire Spark environment locally. That is the promise of Spark Connect.
How Spark Connect Works
Under the hood, Spark Connect:
Uses the DataFrame API as its main communication layer
Sends logical plans (not physical execution steps) to the Spark cluster via gRPC
Executes queries remotely, optimizing performance
Returns results to the client efficiently using Apache Arrow
This separation means you can interact with Spark from any device or language that supports Spark Connect, including Python (PySpark), Scala, and potentially even Go or Rust in the future.
Why Spark Connect? The Problems It Solves
In a nutshell, Spark Connect makes Spark more accessible, robust, and flexible for various use cases. The decoupled architecture provides several advantages that address longstanding issues in Spark’s monolithic design:
Work From Anywhere
Spark Connect allows you to interact with Spark remotely from notebooks, IDEs, web apps, and even edge devices. There is no need to run your code on the cluster’s head node or submit jobs manually.
You can connect to Spark just like a database!
More Stability in Shared Clusters
Ever had someone’s massive Spark job crash the entire cluster?
With Spark Connect, each application runs in its own process, isolating workloads. If one application consumes too much memory, it will not affect others, making shared environments more stable and predictable.
Seamless Upgrades
Before Spark Connect, upgrading Spark was painful. Every application needed to update its dependencies in sync with the cluster. Now, Spark Connect abstracts the execution layer, meaning client applications can keep running even if the cluster is upgraded. This makes maintenance and upgrades much smoother.
An Open, Multi-Language Ecosystem
Previously, connecting local applications to a Spark cluster often required third-party tools like Apache Livy or complex custom integrations. Now, Spark provides a built-in, standardized approach. Since it communicates using logical plans rather than language-specific objects, Spark Connect makes it easier to develop Spark clients in different languages.
Think of it like JDBC/ODBC for DataFrames, a universal protocol allowing different tools and languages to query Spark clusters effortlessly.
How Spark Connect Compares to Traditional Spark Execution
You can see the comparison between the traditional spark way of doing things and the new spark connect:

Key Benefits of Spark Connect
Improved Developer Experience: Users can develop, test, and debug Spark applications interactively from their favorite IDEs.
More Stable Multi-Tenant Clusters: Applications run in separate processes, reducing crashes caused by a single application.
More Efficient Debugging: Developers can inspect and modify queries before execution, reducing wasted computation. We will explore this in future part 2 post.
Expanded Spark Use Cases: Enables Spark to be used in lightweight applications, such as web services or cloud-based tools.
Conclusion
Spark Connect is a major leap forward in Spark’s evolution, providing flexibility, stability, and an improved developer experience. By decoupling Spark’s execution layer from the client, it allows remote access, better debugging, and easier integration into various environments.
In Part 2, we will explore how Spark Connect enables live debugging, improves performance, and reduces iteration time for Spark developers.
Stay tuned!
https://spark.apache.org/docs/4.0.0-preview1/spark-connect-overview.html
Thanks for the post. I didn't know that spark connect is not existing today. (With databricks-connect, I thought a native version had always been there).
Few questions.
1) Isn't a spark application a.k.a driver process ? In your post I see, both referred as separate items.
2) This may be something you planned to cover in part -2. How is the resource isolation planned, is that something to do with FAIR pools ?
Spark always followed lazy evaluation approach. I am wondering if I have a spark job doing hundreds of transformation using Dataset APIs, JBDC from other database, reading from HDFS. In this scenario, how execution will happen? my second question is will this introduce too much traffic over spark connect? my third question is how are we going to configure the resources needed for a given complex spark job?