
Transformations vs. Actions in Apache Spark: The Key to Efficient Data Processing
Understanding the Core Mechanics Behind Spark's Lazy Evaluation Model

When I first started working with Apache Spark, there was one concept that took me a while to fully grasp but completely changed how I approach data processing: understanding the difference between transformations and actions.
In this post, I'll explain why this distinction is crucial, share my experiences, and help you avoid common pitfalls that can tank your Spark jobs' performance.

Spark's Laziness: A Feature, Not a Bug
Let's start with a fundamental truth about Spark: it's lazy.
Spark deliberately delays data movement for as long as possible. Why? Because this laziness allows Spark to:
Optimize the execution plan before touching any data
Minimize unnecessary data transfers
Pipeline operations to reduce I/O
This laziness is implemented through the distinction between transformations and actions.
Understanding this distinction is the key to writing efficient Spark applications.
The Two Worlds of Spark: Logical Plan vs. Data
When working with Spark, we're operating on two distinct levels:
The Logical Plan Level: This is where DataFrames exist. They're not actual data, but rather "recipes" for computing data. Think of them as blueprints or instructions.
The Data Level: This is where the actual data resides and gets processed across the cluster.
A crucial insight: DataFrames are not data!
They're just specifications for how to compute data. This is fundamentally different from, say, Pandas DataFrames, which actually hold the data in memory.

Transformations: Building the Recipe
Transformations are operations that:
Create a new DataFrame from an existing one
Are lazy (they don't execute immediately)
Only build up the logical query plan
Return a DataFrame (not the actual data)
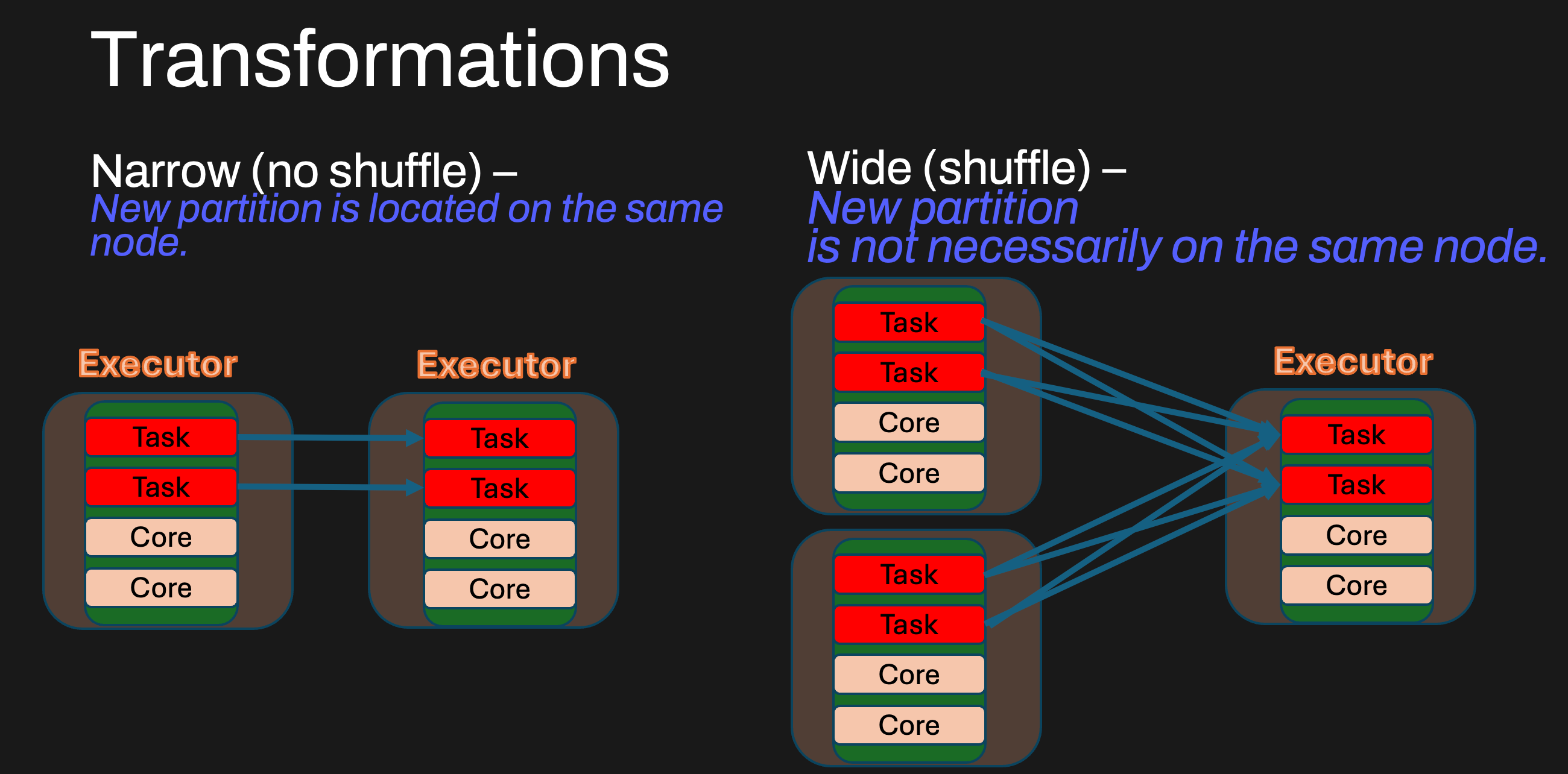
Narrow vs. Wide Transformations
Transformations can be classified into two types:
Narrow transformations: Each partition of the parent DataFrame is used by at most one partition of the child DataFrame. Examples include
filter(),map(), andwithColumn(). These transformations are efficient because they can be executed in a pipeline without requiring data to be shuffled across partitions.Wide transformations: These require data to be reshuffled across the cluster because a single output partition depends on multiple input partitions. Examples include
groupBy(),join(), andrepartition(). These transformations introduce shuffle operations, which are costly as they require network communication and disk I/O.
Because wide transformations require a shuffle, they significantly impact performance. Understanding when a transformation introduces a shuffle helps optimize Spark jobs, you can check our previous post on shuffle for more info.
Common examples of transformation include:
# These are all transformations - nothing gets computed yet!
filtered_df = df.filter(df.age > 25)
selected_df = df.select("name", "age") j
oined_df = df1.join(df2, "user_id")When you execute code like this, Spark just takes note: "Okay, when someone actually needs this data, I'll need to filter by age, select these columns, or join these tables." But it doesn't actually do anything with the data yet!
Actions: Finally Moving Data
Actions are operations that:
Trigger the execution of the transformation plan
Actually process data and produce results
Return something other than a DataFrame, or have a side effect
Common examples include:
# These are all actions - they trigger computation!
count = df.count() # Returns a number
first_row = df.first() # Returns a Row object
df.show() # Displays data, returns nothing
df.write.parquet("path") # Writes data, returns nothingWhen you call an action, Spark says, "Alright, time to stop planning and start executing!"
A Real-World Lesson: The Cost of Unnecessary Actions
During a project I encountered a data scientist working with customer transaction data, he initially approached it like I would with Pandas:
# Load the data
transactions = spark.read.parquet("s3://data/transactions/")
# Filter to recent transactions
recent = transactions.filter(col("date") > "2024-01-01")
print(f"Recent transactions: {recent.count()}") # Action 1!
# Find high-value transactions
high_value = recent.filter(col("amount") > 1000)
print(f"High-value recent transactions: {high_value.count()}") # Action 2!
# Get average transaction value
avg_value = high_value.select(avg("amount")).collect()[0][0] # Action 3!
# Save the high-value transactions
high_value.write.parquet("s3://data/high_value_transactions/") # Action 4!The job took over 20 minutes to run on a decent-sized cluster. After examining the Spark UI, I showed him his mistake: each action was recomputing the entire chain of transformations from scratch!
He was essentially reading the entire dataset from S3 four separate times!
Here's how I helped him fix it:
# Load the data
transactions = spark.read.parquet("s3://data/transactions/")
# Filter to recent transactions
recent = transactions.filter(col("date") > "2024-01-01")
recent.cache() # Mark for caching
recent.count() # Materialize the cache
# Now the remaining operations use the cached data
high_value = recent.filter(col("amount") > 1000)
high_value.cache() # Mark for caching
count = high_value.count() # Materialize cache and get count
print(f"Recent transactions: {recent.count()}")
print(f"High-value recent transactions: {count}")
print(f"Average high-value amount: {high_value.select(avg('amount')).collect()[0][0]}")
# Save the high-value transactions
high_value.write.parquet("s3://data/high_value_transactions/")
The job now completed in under 5 minutes - a 4x improvement!
The Power of explain() in Debugging Performance
One of the most useful tools in Spark is the explain() function, which helps understand how Spark will execute a query without actually running it. Since Spark optimizes transformations before execution, explain() allows us to:
Inspect the logical plan (the sequence of transformations before execution)
Identify potential shuffles introduced by wide transformations
Verify whether predicate pushdown, partition pruning, or other optimizations are applied
For example:
df.filter(col("amount") > 1000).groupBy("user_id").agg(sum("amount")).explain()This prints out the logical and physical execution plans, allowing you to spot inefficiencies before running an action. Using explain() early in development can prevent costly mistakes. You can checkout our previous post that went into how to use explain() properly.
Common Misconceptions
Misconception 1: "Transformations execute immediately"
# This completes instantly, even with terabytes of data
df = spark.read.parquet("huge_dataset.parquet")
filtered = df.filter(col("important") == True)The above code doesn't actually read any data. It just builds a plan. Many newcomers are surprised when these lines execute instantly, even with terabytes of data. The real work happens when you call an action.
Misconception 2: "I need to save each step in a new variable"
# These are equivalent in terms of performance:
df1 = df.filter(...)
df2 = df1.select(...)
df3 = df2.groupBy(...).agg(...)
# Same performance as above:
result = df.filter(...).select(...).groupBy(...).agg(...)Since DataFrames are just execution plans, not data, there's no performance penalty to creating "intermediate" DataFrames. Choose the style that makes your code most readable!
Misconception 3: "Cache() immediately stores data in memory"
df.cache() # NOTHING HAPPENS YET!
# ... more code ...
df.count() # NOW the data is actually cachedcache() is actually still lazy!
It only marks a DataFrame for caching - the actual caching happens when the first action is executed.
Pitfalls to Avoid
Recomputing expensive transformations: Always cache DataFrames that will be reused in multiple actions.
Too many actions for debugging: Avoid adding
.show()or.count()throughout your code just to see intermediate results. Each one triggers computation!Collecting too much data to the driver: Never use
.collect()on large DataFrames. The driver node has limited memory.Chaining too many transformations: While you can chain many transformations, extremely long chains can cause memory issues during the planning phase.
Not accounting for shuffle costs: Wide transformations (like
groupByandjoin) that cause data shuffling are much more expensive than narrow transformations (likefilter).
Best Practices
Embrace laziness: Chain your transformations and let Spark optimize the whole plan and use explain().
Cache strategically: Cache DataFrames that will be used multiple times.
Use the right action for the job: Don't use
collect()whencount()orshow()would suffice.Push processing down: Filter early to reduce data volume before expensive operations.
Monitor with Spark UI and dataflint: Check for repeated stages or unexpected jobs to identify inefficiencies and add dataflint for more insights on performance.

Conclusion
Understanding the difference between transformations and actions is essential for efficient Spark programming. By leveraging Spark's lazy evaluation model properly, you can achieve significant performance improvements in your data processing tasks.
Remember: Spark delays data movement as long as possible to optimize your query. Only actions move data - transformations just build the plan. By respecting this design, you'll avoid unnecessary computation and write more efficient Spark applications.
What has been your experience with Spark's transformation and action model? Drop a comment below with your own tips or questions!